Supplemental results («Сопли Google»). Существует ли основной и дополнительный индекс?
Уже довольно давно обсуждается тема наличия основного и дополнительного индекса. Суть сводиться к тому, что Крупнейшая поисковая система давно-давно сообщила, что имеется основной индекс и дополнительный. Хорошие, качественные страницы попадают именно в Основной индекс, а плохие, соответственно – в дополнительный.
При поиске сперва ищется информация только по основному. И только если там ничего не находится – тогда уже обращается и к дополнительному индексу. Как вы понимаете, такое бывает крайне редко, и найти что-то по дополнительному индексу. Кроме того, от соотношения страниц в основном и дополнительном индексе оценивается и само качество сайта.
Посмотреть основной индекс сайта можно, введя запрос
Site:site.ru/* (или site:site/&).
Например, рассмотрим данный сайт (marketnotes.ru).
Всего страниц:
Site:marletnotes.ru = 160 страниц.
В основном индексе: site:marketnotes.ru/* = 28
В дополнительном индексе: site:marketnoets.ru –site:marketnotes.ru/* = 118
Хочу обратить внимание, что 118+28 не равно 160, 14 страниц потерялось. Такое бывает, но обычно число не велико, так что терпимо.
Таким у меня на сайте только 28/160=17,5% страниц в основном индексе (что, вобещм-то плохо). И я догадываюсь откуда. Криво поставлен блог и он дублирует основные страницы. Ну это поправим. Теперь, собственно говоря, задача выяснить, влияет ли как-то это на выдачу.
Проведем небольшой анализ. Возьмем топ страниц входа по Google и выясним, находятся ли они под «соплами Google» или же в основной выдачи? Для этого я воспользовался Google.Analytic (кому-то нравился Яндекс.Метрика или любая другая система – не принципиально. Кстати, в одном из следующих обзоров нужно будет сравнить их, посмотреть, кто больше врет).
Итак, в GA настроим фильтр по источникам на только Google, и перейдем на вкладку Самые популярные страницы входа.
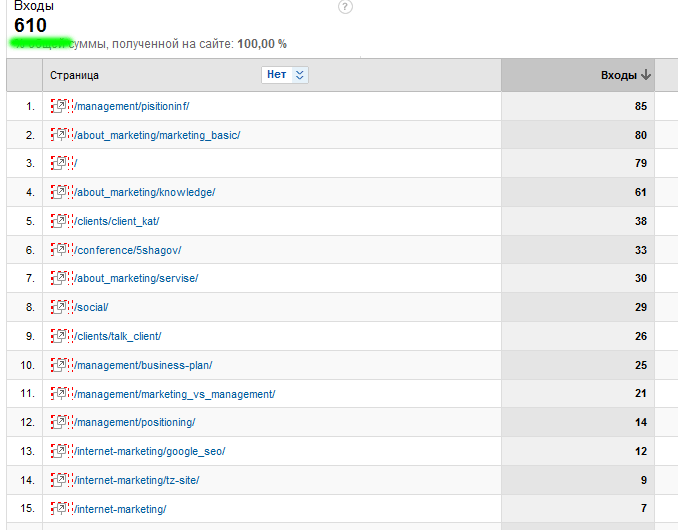
Ну а теперь все что остается сделать, это посмотреть, какие из этих страниц находятся по основной выдачи, а какие нет. Для наглядности, сделал все в Экселе. Вот что получилось:
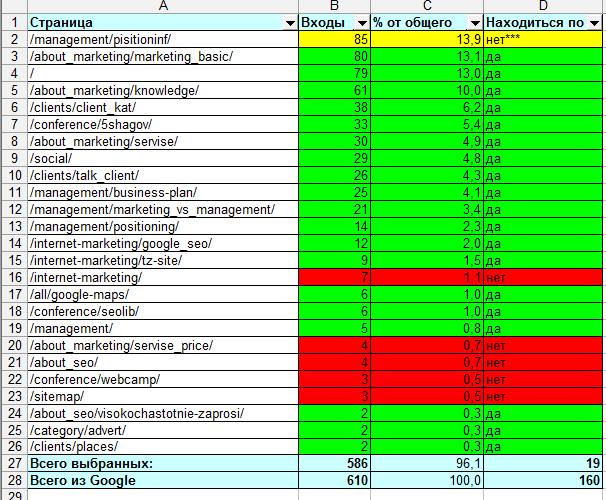
Страница /management/pisitioninf/ — так же была в основной выдаче, однако, я заметил что неверно ее написал, и переименовал в /management/positioning/, а старую удалил вручную через Google Webmaster Tools, однако, статистика по ней считалась.
В итоге, на страницы под /* приходится 565 переходов, т.е. 92,6% от всех 610 переходов.
Возможно, мой сайт – неправильный? Глупо судить о тенденции по 1 примеру. Возьмем другой контентный сайт: brandars.ru
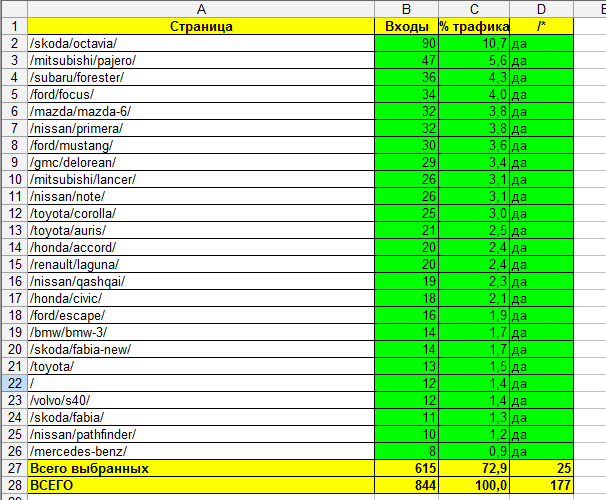
Но это вообще очень качественный сайт, тут 85 страниц в основном индексе из 177 (48%). Получаем, что на страницы в основной выдаче 73% (и это не все).
И последний пример, Интернет-магазин из украинского сегмента (сайт светить не буду, уж извините. Придется поверить на слово):
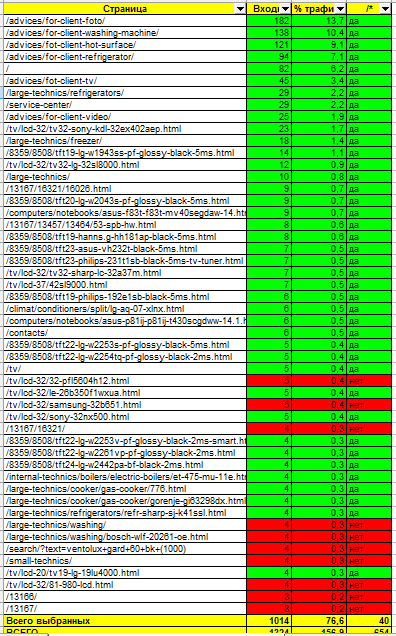
Тут еще довольно длинный хвост низкочастотников, как и положено Интернет-магазину, поэтому особо все рассчитывать не будем. По общим показателям: в основном индексе: 11% страниц.
Трафик на страницы из основного индекса: 73%.
В среднем по всем трем сайтам, на страницы, которые выдаются под /* приходится порядка 80% всего трафика с Google. Тенденция подтверждается как в RU так и в UA сегменте.
Как именно Google делит эти страницы, что сделать, чтоб их было побольше – вопрос отдельный. Целью данного анализа было всего лишь проверить версию о существовании этого эффекта «Supplemental results» по запросу /*
И последнее, на закуску. Таблица без особых пояснений (кликните для увеличения).

Весь поисковый трафик сайта распределяется так: 60,6% с Яндекса, 36,5% с Google.
92% всего трафика с Google приходится на страницы, которые в основном индексе.
86,7% всего трафика с Яндекса приходится на страницы в основном Индексе.
Общий показатель: 88,8% всего поискового трафика приходится на страницы, которые Google показывает как в основном индексе (по запросу с /*).
Общий вывод: эффект фильтра Supplemental results все еще существует, что бы там не говорили Гуру и представители ПС. На страницы в основном поиске приходится подавляющее (более 80%) всего поискового поиска Google. Замечено, что на эти же страницы, хоть и в немного меньшей степени, приходится и трафик с Yandex. Это говорит о том, что обе поисковые системы примерно одинаково определяют качество страниц и показатели Google в принципе можно применять и к Яндексу.